🛒Enhancing E-Commerce Search: Leveraging Keywords and Semantics for Better Results beyond Hybrid Search

We are proud to introduce Query Attribute Modeling - a groundbreaking approach to reshaping enterprise search. Learn more about how this innovative technique accelerates retrieval, boosts efficiency, and transforms the landscape of precision in every search query

Search technology is at a pivotal juncture, with users desiring more personalized and conversational interactions. While keyword-based search, exemplified by Google, lacks contextual understanding, semantic search systems, driven by SOTA Encoder models, often sacrifice precision, due to their limitations in understanding numerical terms.
Anticipating an evolved search experience, the emerging Query Attribute Modeling (QAM) introduces a hybrid approach that harmonizes conversational and keyword-based capabilities. Before delving into QAM specifics, it's essential to review existing search systems, and understand their tradeoffs between precision, recall, and user experience. This backdrop highlights the necessity for a versatile retrieval architecture that combines the strengths of both search paradigms.
Search Mechanisms
There are majorly three types of search that currently are leveraged across different use cases -
- Keyword search relies on specific words or phrases to retrieve information, making it the go-to method for users seeking quick and direct results, however misses out on results that are very similar syntactically, thereby narrowing the search results.
- Semantic search represents a context-aware and concept-driven approach, understanding the meaning behind words by considering context and relationships between entities for more accurate and contextually relevant results, but overlooks some very specific details (maybe industry specific jargons, critical keywords) thereby not yielding best results
- Hybrid Search stands at the crossroads of traditional search methods, blending the quick precision of keyword search with the context-aware richness of semantic search. Independently, it represents a groundbreaking evolution, where the power of keywords harmonizes with the depth of semantics, reshaping the landscape of search technology
Is Hybrid Search Enough ?
In the dynamic landscape of Hybrid Search, a critical challenge surfaces in effectively blending keyword and semantic results. Despite its promise, Hybrid Search falls short in understanding user intent seamlessly, particularly when intricate metadata is involved. For example, in a shopping query like "black dress for a friend's birthday," Hybrid Search's amalgamation of keyword and semantic results, often reliant on complex embedding, may not discern user intent efficiently.
This prompts a key question: Can we optimize the process by leveraging enterprise data structure to extract metadata tags from user queries? Enter Query Attribute Modeling, a pivotal strategy addressing these limitations head-on. It strategically filters the semantic search space based on specific "key attributes," offering a refined and efficient search process in the Hybrid Search environment.
Query Attribute Modeling
Query Attribute Modeling a.k.a QAM is a method meticulously crafted to elevate precision in product searches. As its first step, it leverages Query Decomposition that dissects user queries into specific product attributes such as material, brand, color, and age, meticulously aligning with enterprise metadata. By judiciously filtering products based on these attributes, the search space is efficiently refined, furnishing users with bespoke results tailored to their specified preferences.
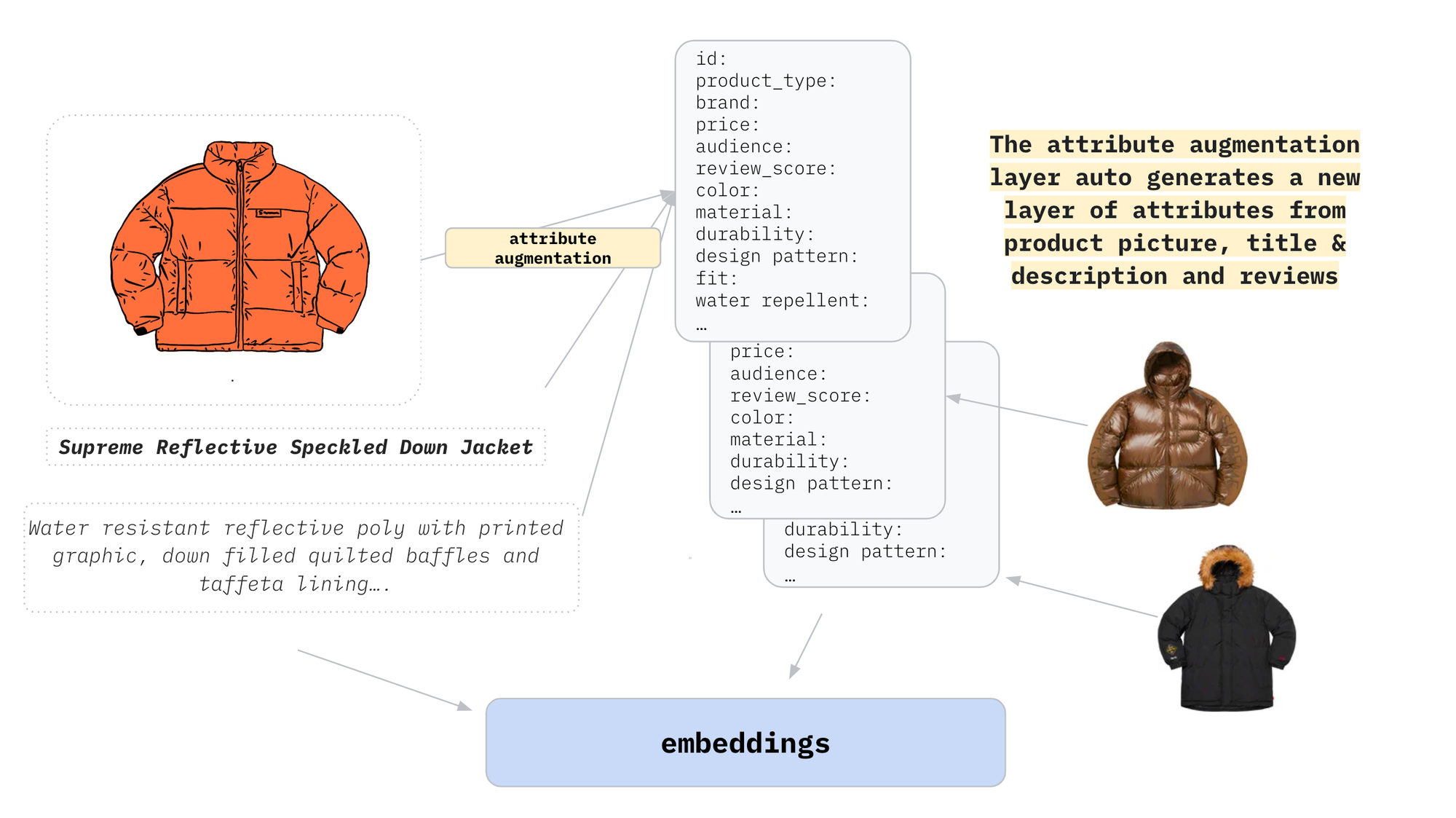
Within the domain of Query Attribute Modeling, the discerning decomposition of queries into metadata tags and semantic context specifiers assumes a pivotal role. The initial filtration of data based on metadata tags effectively truncates the search space, succeeded by semantic comparisons with user reviews to imbue search results with contextual richness. This methodical two-step process adeptly accommodates diverse user search behaviors, thereby augmenting precision and elevating the overall user experience.
Project and Experimentation
In collaboration with UCLA MS in Business Analytics students, our experimentation leveraged the Amazon Toys Reviews dataset, meticulously granulized at the review level for each product. Recognizing the limitations of direct semantic or keyword searches on descriptions, we prioritized robust feature and attribute engineering. This strategic approach, emphasizing feature engineering over model complexity, proved transformative in enhancing predictive accuracy, interpretability, and generalization. Well-crafted features not only capture essential patterns but also improve model interpretability and robustness, showcasing superior performance compared to intricate model designs."
In implementing feature engineering techniques and text cleaning with spaCy and NLTK, we derived, cleaned, and imputed existing features. The resulting data dictionary encapsulates key product details such as name, manufacturer, price, star rating, stock availability, number of reviews, description, consumer review, preferred age, and the number of players required. This meticulous process ensures a robust, adaptable model aligned with intrinsic data characteristics, reflecting our commitment to effective, interpretable, and maintainable data analysis and machine learning practices.
From user query to top N search results, our comprehensive pipeline navigates four pivotal steps, ensuring a refined and personalized search experience.
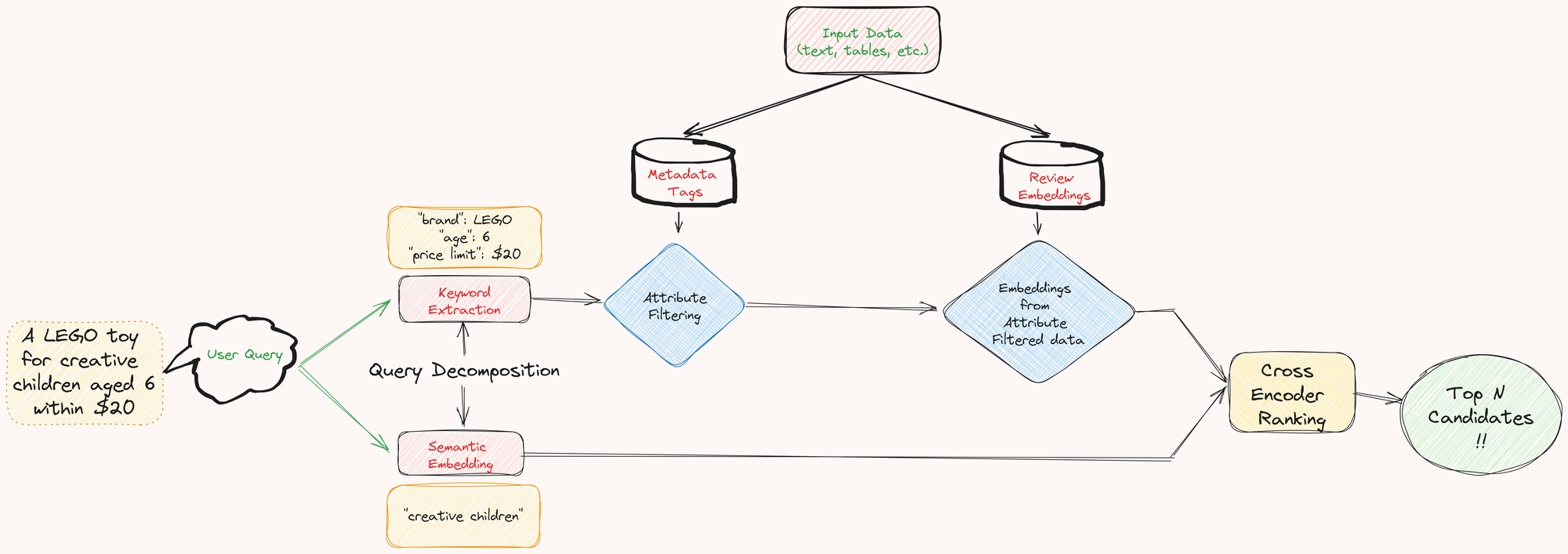
Step 1: Query Decomposition
At the inception of our process, we harness the formidable language capabilities of gpt-3.5-turbo to execute query decomposition. This advanced LLM adeptly dissects user queries into two crucial components. First, metadata tags are meticulously extracted, capturing essential aspects such as brand, preferred age limits, and price constraints. Second, the semantic facet unravels the explanatory layers inherent in the user queries.
Step 2: Leveraging Metadata Tags for Enhanced Search Precision
At this stage, our focus gravitates towards the meticulously extracted metadata tags, encompassing elements like material, brand, and color. Take, for example, a search query for a "little black dress," where the "black" tag plays a pivotal role in refining the dataset to highlight only relevant items. Furthermore, post-filtration, the streamlined dataset significantly improves the efficiency of subsequent semantic searches, leading to enhanced search speed and relevance.
Step 3: Capturing Contextual Nuances through Review Embeddings
In the third step of our refined pipeline, review texts and subjective query components undergo a sophisticated transformation into embeddings. The all-mpnet-base-v2 model, renowned for its prowess in contextual understanding, plays a pivotal role. This model encodes qualitative aspects present in the review texts, further refining our grasp on the intricate characteristics of the products. The dual approach sharpens our ability to capture the nuanced sentiments expressed in user reviews, contributing to a richer understanding of user preferences.
Step 4: Final Ranking
The culmination of our pipeline unfolds in Step 4—Final Ranking and Results. Here, we introduce a powerful bi-encoder and cross-encoder duo for the ultimate ranking of search results. Review embeddings, carefully filtered by metadata tags, seamlessly integrate with user query embeddings. This convergence sparks a cosmic dance of cosine similarity computations, where higher scores signify a profound resemblance between product reviews and user queries.
Example in Action
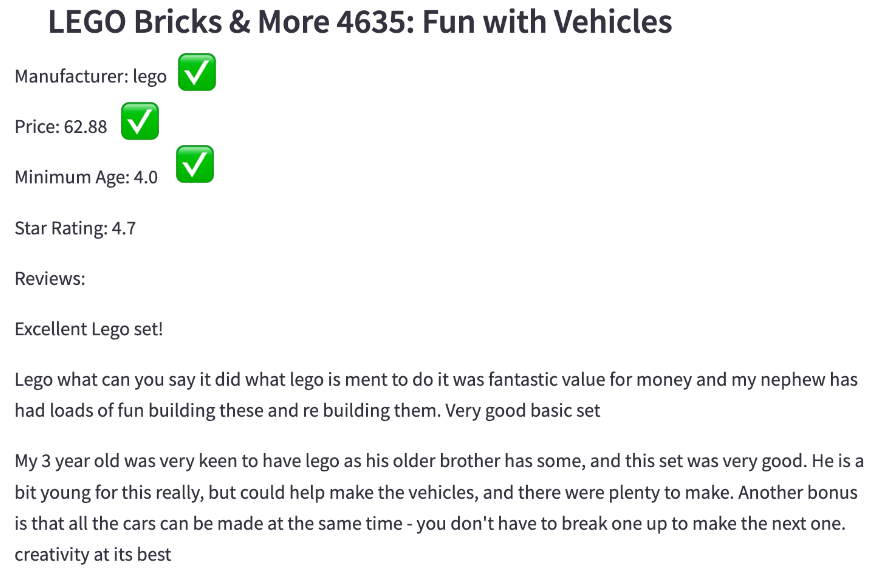
To give life to the content discussed above, we developed a front-end on Streamlit comparing the keyword search approach with our QAM. For instance, a query like the one in the above infographic - “Find a LEGO set between $50 and $100 for children under 5.” We can clearly see how the results are in line with what we are looking for in the QAM method whereas keyword search fails to grasp the nuance

Results
In the realm of experimentation, our journey encountered a unique challenge—a relatively modest dataset comprising 40,000 reviews for all products collectively. Recognizing the importance of robust statistical backing for our outcomes, we opted for a pragmatic approach. The impact of our endeavors was measured through the lens of average precision at 5, a metric widely acknowledged for evaluating the relevance of search results.
For context, precision at k (P@k) is a metric that gauges the accuracy of the top k results returned by a search system.
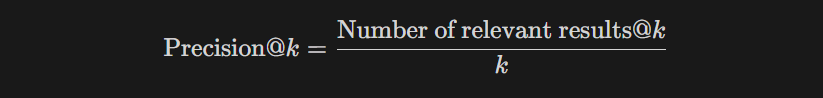
Despite the absence of labeled outcome data, we analyzed how well hybrid search stacked up against keyword search, aligning with our expectations for relevant results. In our pursuit of comprehensive evaluation, we diversified our queries across different dimensions—leveraging just metadata tags, solely semantic tags, and a harmonious blend of both. Approximately 100+ queries were meticulously crafted to ensure a nuanced exploration of the model's capabilities. The benchmark for comparison was set against the standard keyword search results for the same queries.
Delving into the outcomes, the Average Precision at 5 for our Query Attribute Model showcased a commendable lift of approximately 2.22 when compared to the traditional keyword search and a lift of 2.16 over the semantic search. This uplift highlights the model's prowess in enhancing precision, even within the constraints of a smaller dataset, and positions it as a promising advancement in search methodology. As we navigate through the landscape of limited data, these results stand as a testament to the effectiveness and reliability of our approach in delivering more accurate and relevant search outcomes.
Next Steps
- Moving beyond manual instructions, our aim is to empower the Language Model (LLM) API to autonomously identify relevant keyword tags directly from user queries. This shift eliminates the need for explicit guidance, enhancing the dynamism and adaptability of our query deconstruction process.
- Expanding the scope of semantic understanding, we plan to embed not only queries but also product descriptions, enriching our results with a deeper comprehension of user intent. The integration of powerful vector databases like Qdrant further streamlines information retrieval, contributing to a more sophisticated search experience.
- While our current pilot relies on manual data labeling, we acknowledge the scalability limitations inherent in this approach. The intention is to transition towards scaling our model to standard databases and a more extensive array of queries. This scalability assessment becomes imperative to ensure stability and robustness across diverse datasets, serving as a crucial step in laying the foundation for broader applications.
- Currently, our model focuses on generating embeddings solely from product reviews to understand user sentiment and preferences. However, as we look ahead, a crucial limitation emerges – the absence of product descriptions in the embedding process. Integrating product descriptions alongside reviews is imperative to enhance our model's comprehension of product nuances, ultimately leading to more precise and contextually relevant search results. This enhancement becomes pivotal for a comprehensive understanding of user intent and preferences, addressing a key limitation in our current approach.
About Traversaal.ai
Search is evolving into complex search and Traversaal is the right tool to serve that evolving demand. Traversaal.ai is an innovative B2B platform startup specializing in Large Language Model (LLM) powered products.
Our primary offerings include a comprehensive conversational application with advanced features like authentication, session management, document retrieval, and web search.
Additionally, we provide versatile APIs that seamlessly integrate into organizational ecosystems, enabling the development of robust, domain-specific solutions.
Please email us at hello@traversaal.ai for any queries.
Blog by - Karthik Suresh Menon - NLP Research Scientist | traversaal.ai