“Human in the Loop” - How is GPT trained to Chat?

Written by Batool Arhamna Haider - Head of AI @ traversaal.ai
Large language models (LLMs) went from basic text generation, to snickering at the Turing test - thanks to Reinforcement Learning from Human Feedback (RLHF)!
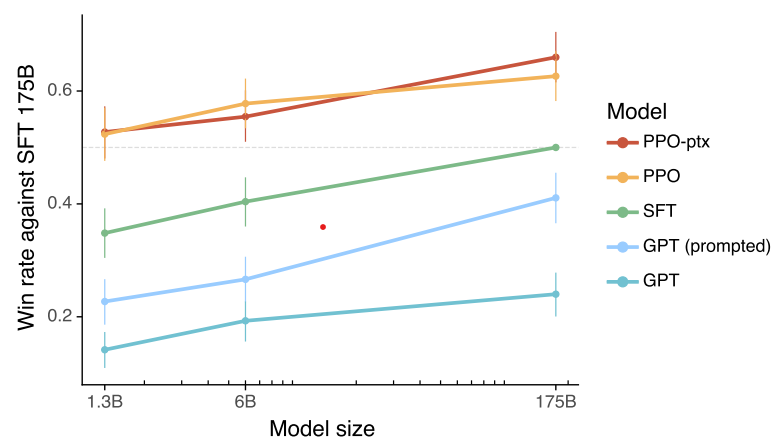
Table of Contents
- Quick Overview
- Level 1 - Pre-training of GPT
- Level 2 - Supervised Finetuning of GPT
- Level 3 - Training the Reward Model
- Level 4 - Fine Tuning GPT using the Reward Model
- Final Result - ChatGPT
- References
A Quick Overview - Training ChatGPT

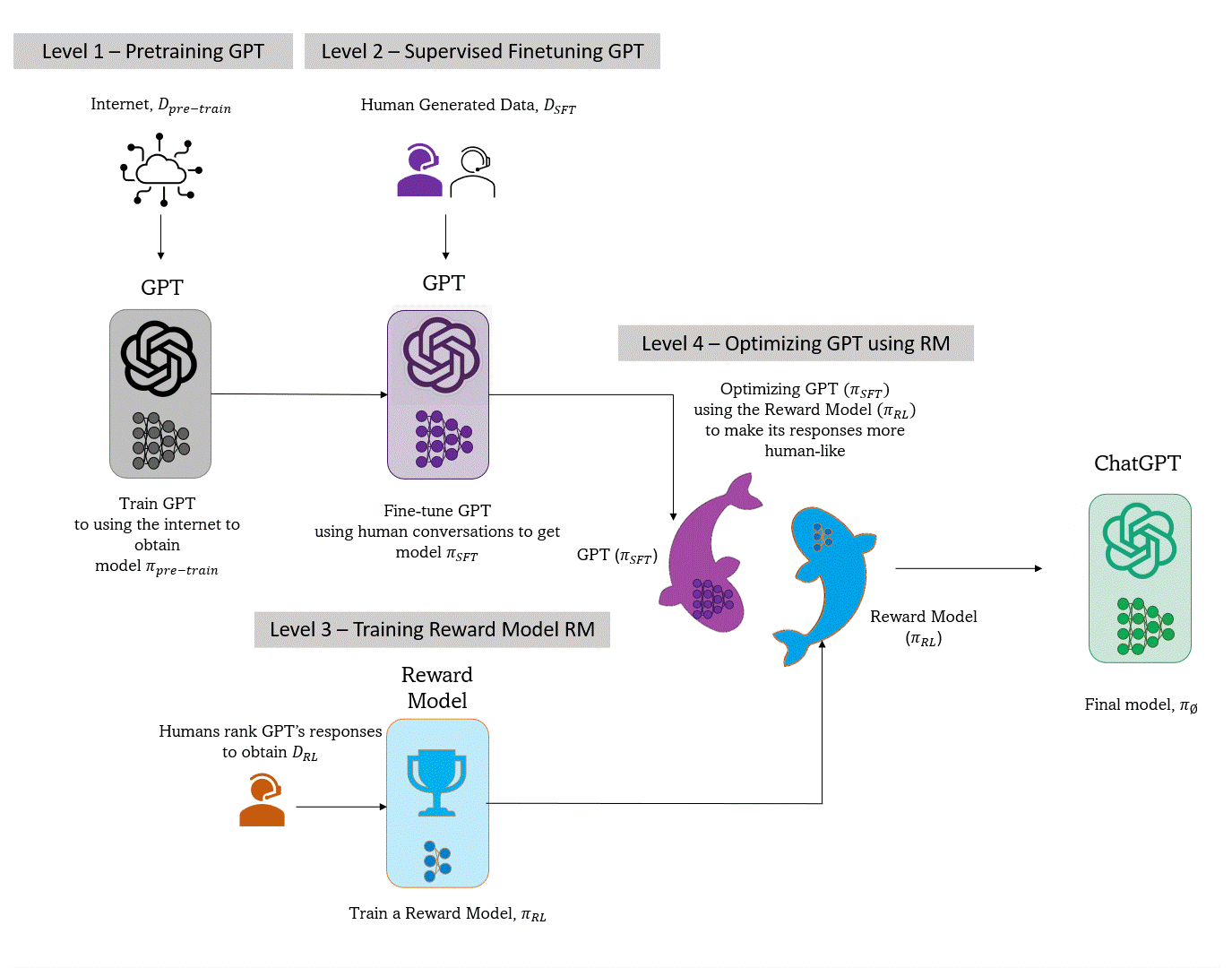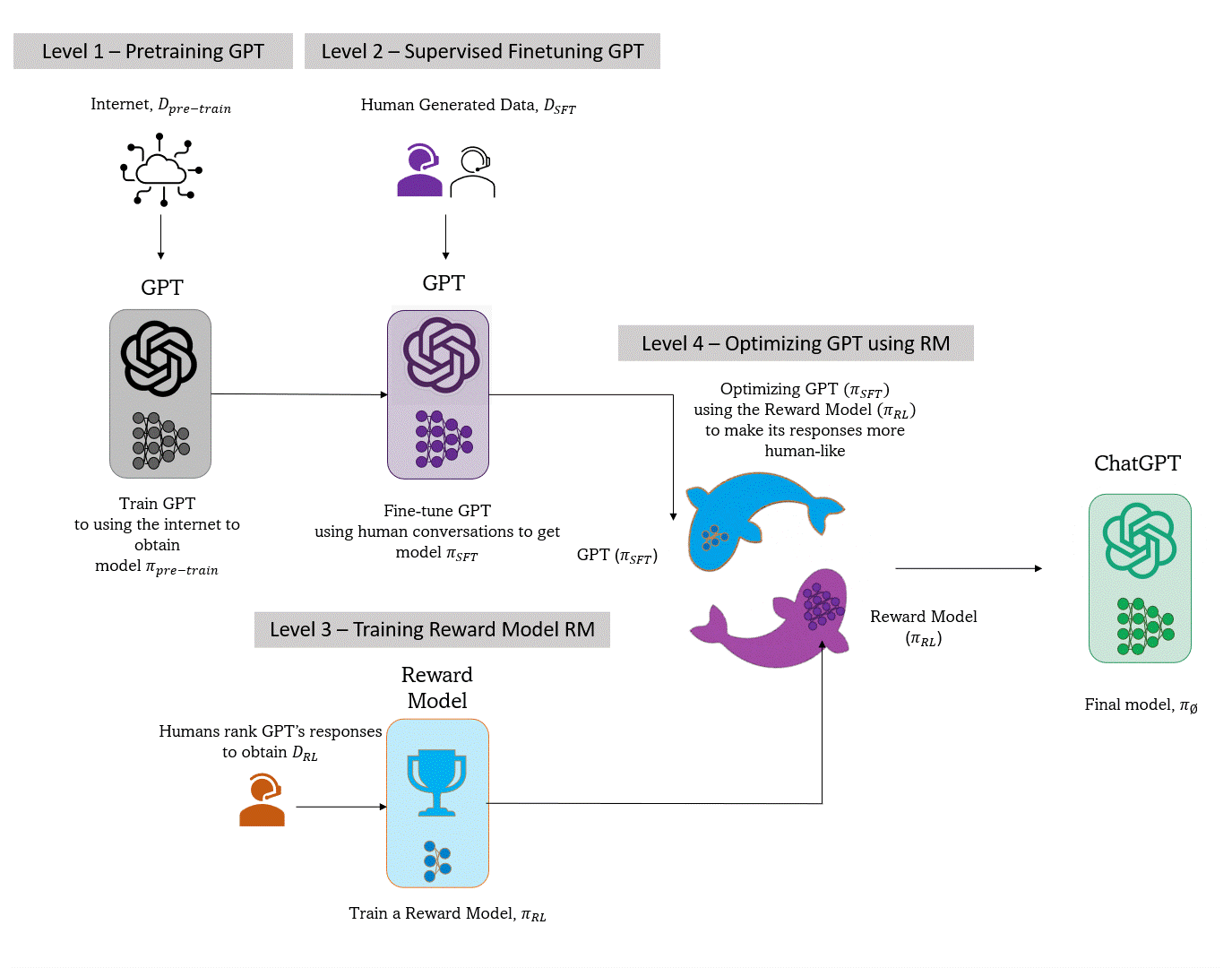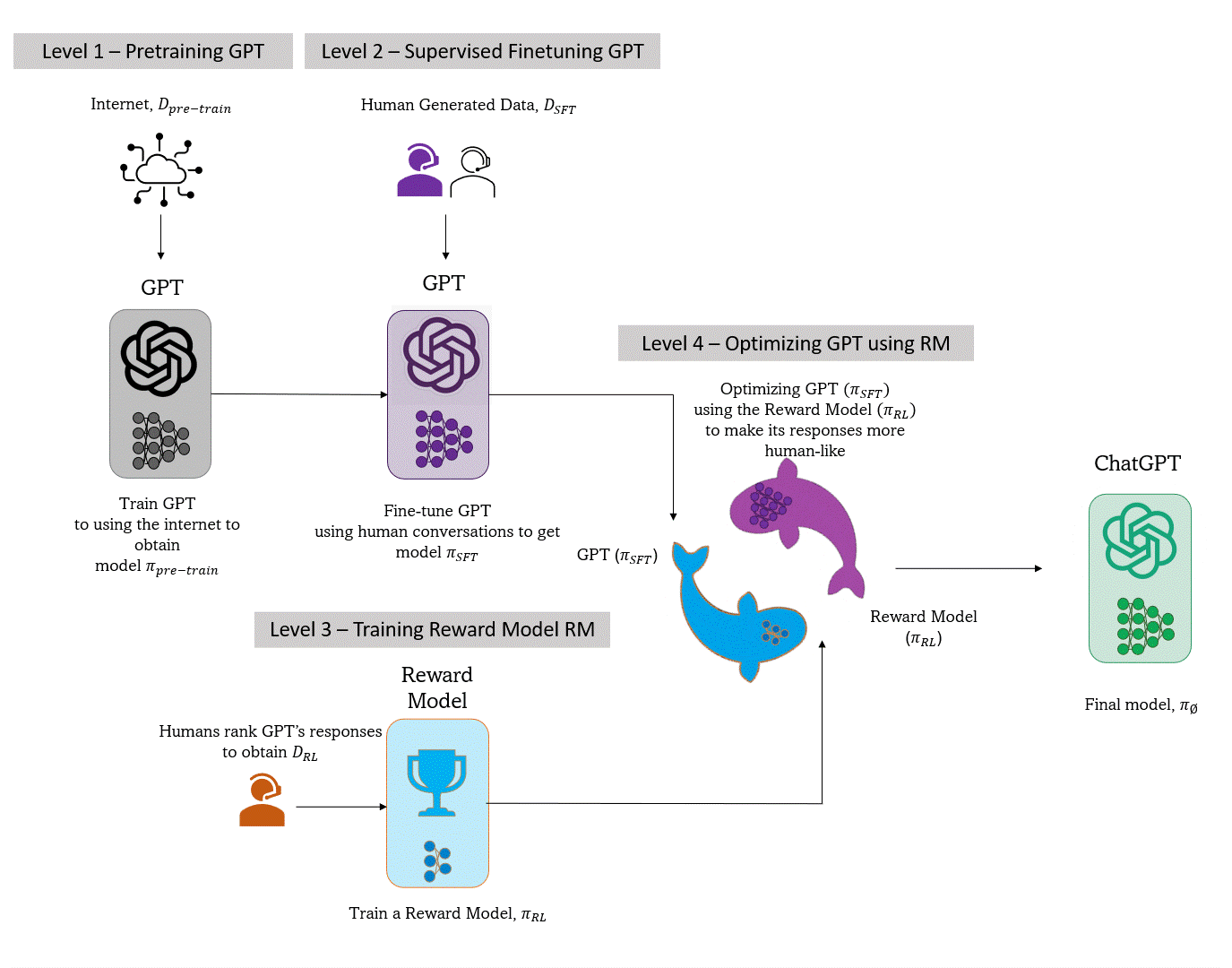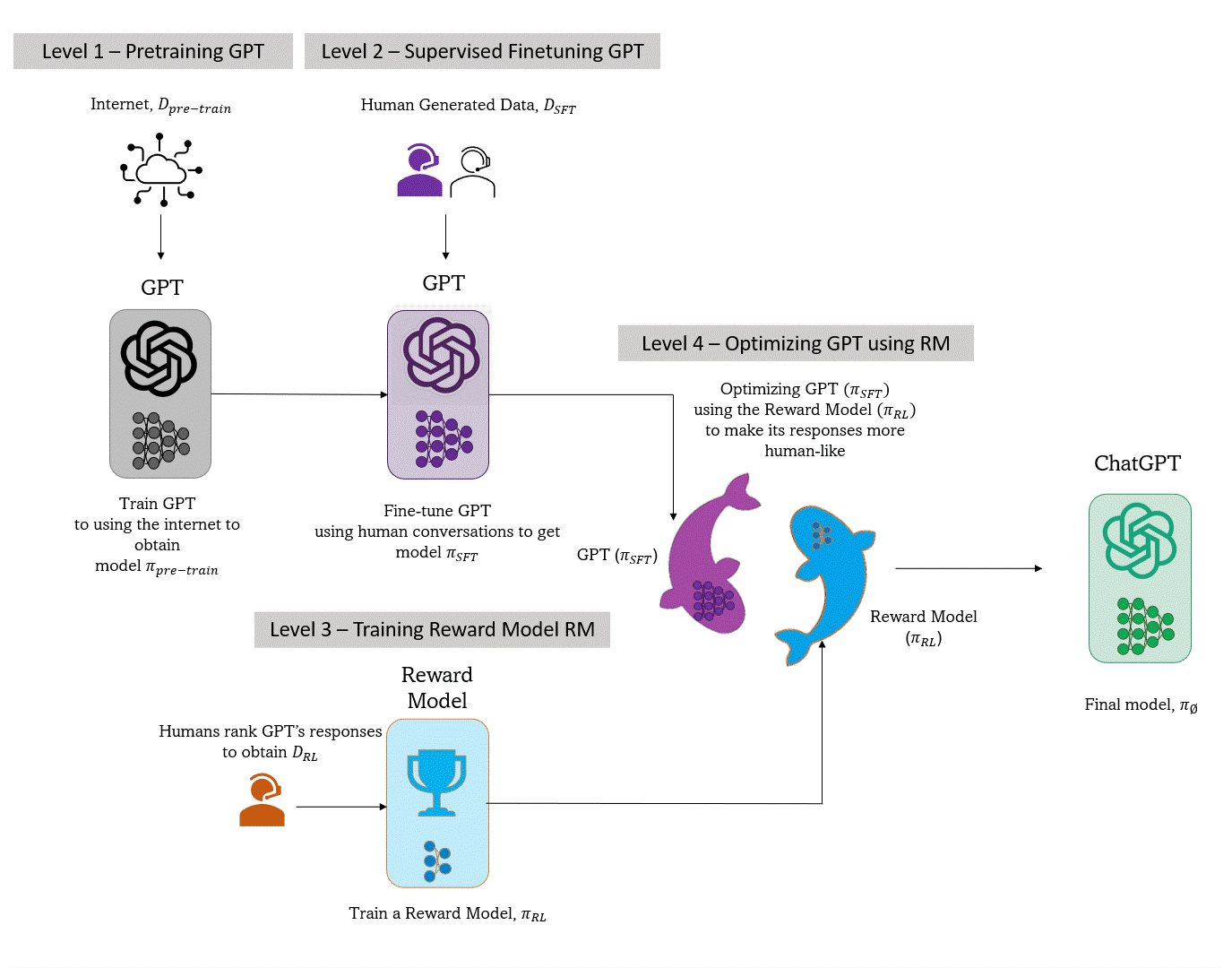
- Level 1 - Pre-train GPT using the internet. The resultant model understands language in general.
- Level 2 - Supervised Finetuning of the pre-trained GPT using human conversations (similar data). The resultant model becomes attuned to human conversations.
- Level 3 - Train a Reward Model to rank fine-tuned GPT responses using data rankings curated by humans
- Level 4 - Further optimize fine-tuned GPT using the Reward Model to favor human preferences.
Level 1 - Generative Pre-Training <Learn the Language>

One-Glance Takeaway
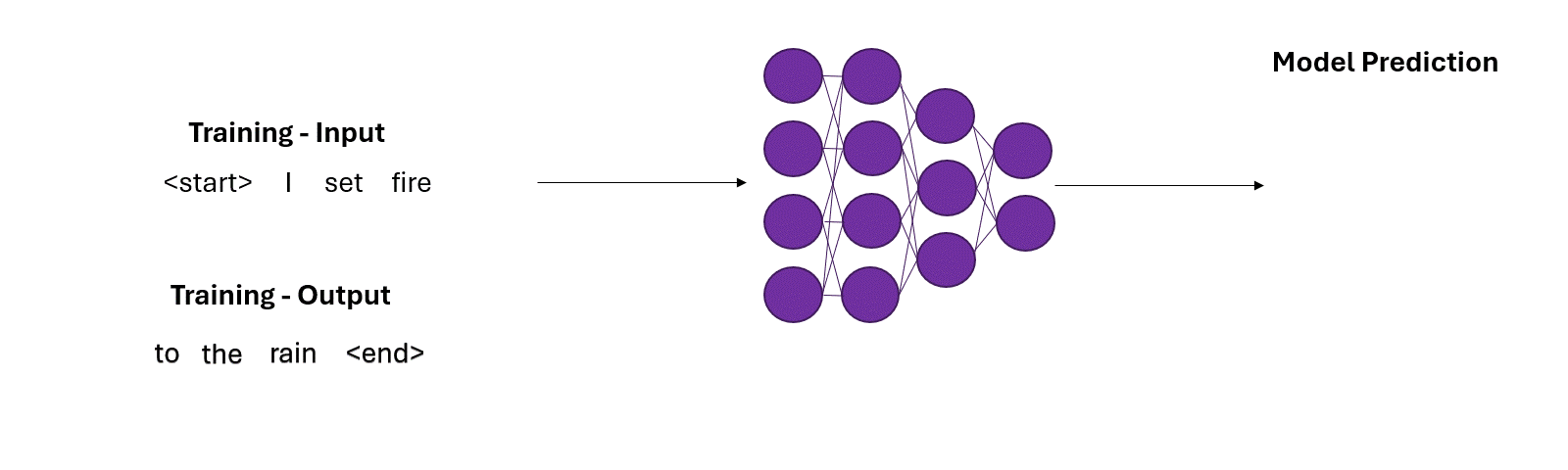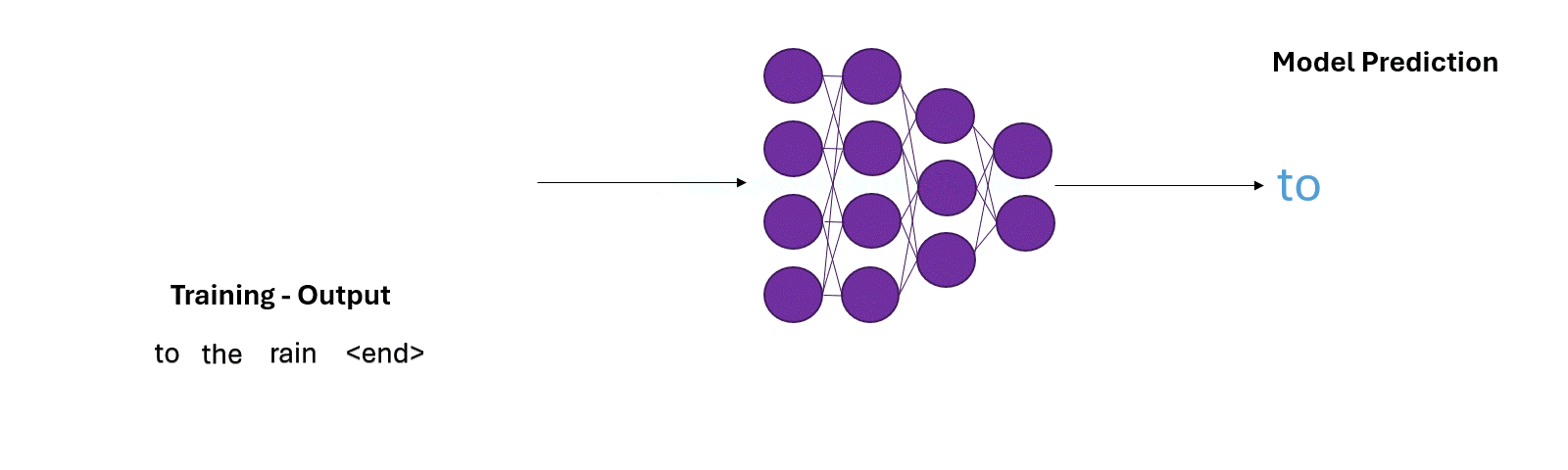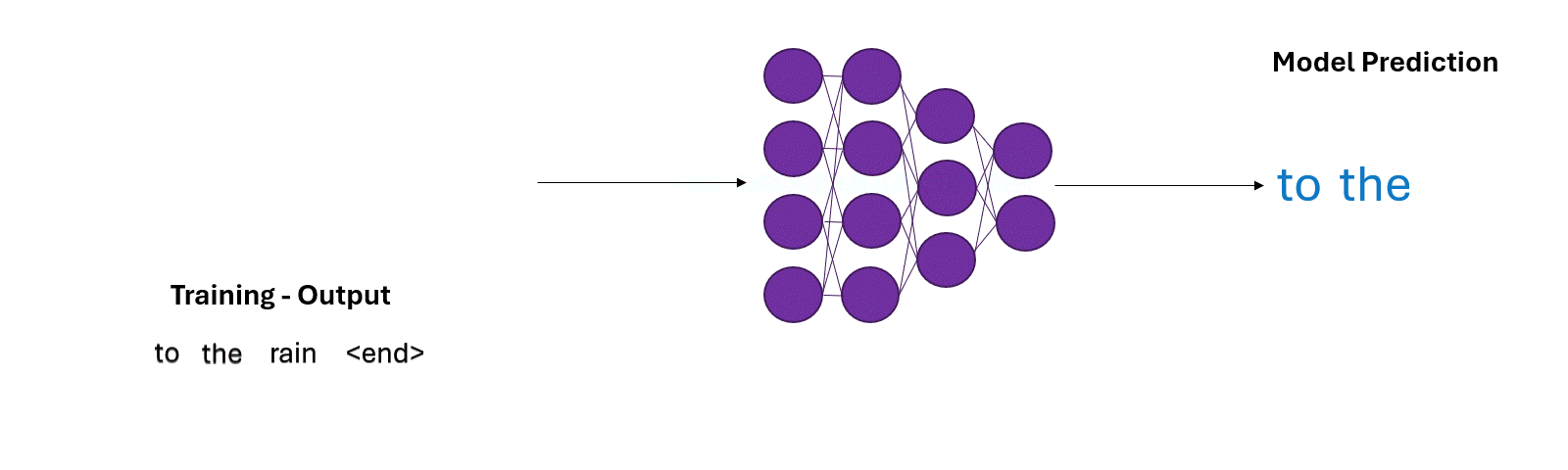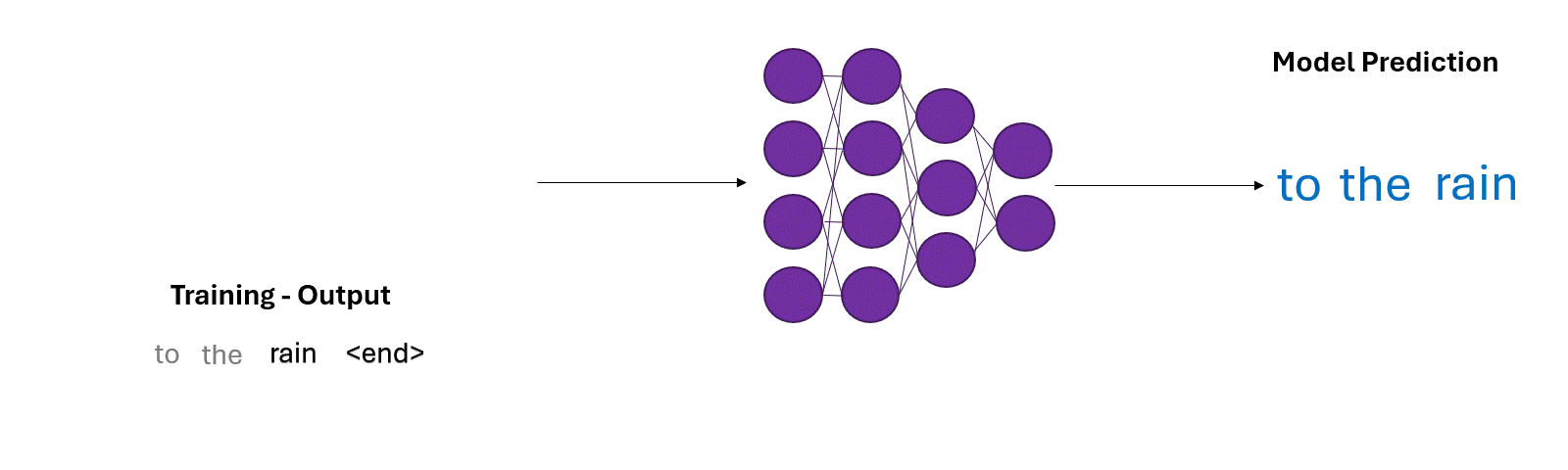
GPT is fed a huge chunk of the internet. It’s task? Given a piece of text, predict the next word.
By learning to complete sentences (pretty much like a little kid), it learns relationship between words, sentence structure and other language nuances.
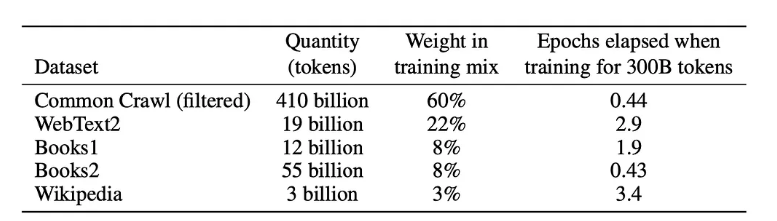
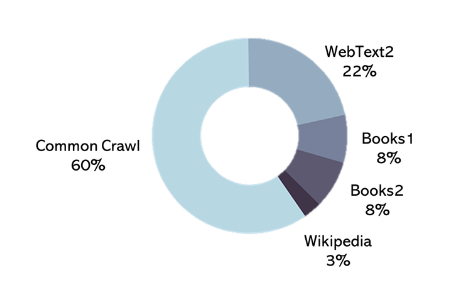
Pre-Training Data, $D_{pretrain}$
The pre-training phase of GPT utilizes a comprehensive and varied dataset as enlisted in Table 1 [1].
Pre-Training Objective
Next word prediction is essentially a classification task, with classes being all the tokens in the model’s vocabulary (we will ignore sub-tokens for simplicity’s sake). Let’s go through an example:
- Input: "But I set fire to the"
- Next word $w_i$: $?$
Given a word sequence, the model assigns probability to all the tokens/words in it’s vocabulary. It then completes the sentence by sampling a word from the vocabulary. The words with higher probability have a higher chance of being chosen as the next word, $w_i$.
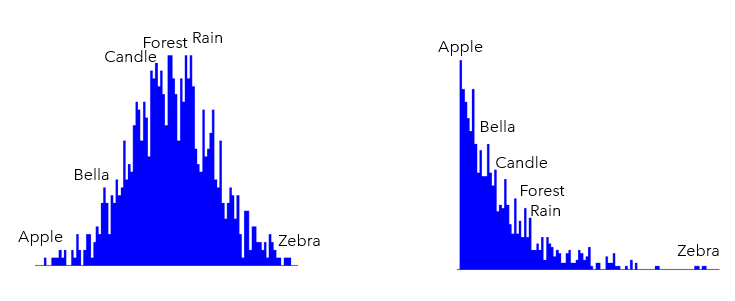
If the model incorrectly chooses/predicts, say, "apple" as the next word $w_{i}$, when the actual next word $w_{true}$ in the training data was, say, "rain", it receives feedback in the form of a loss, L. This loss is used to adjust the model's parameters, to reduce the likelihood of making the same mistake again.
L = − log P ($w_{true}∣ w_{1}, w_{2}, ... , w_{i−1})$
The model's parameters are updated via backpropagation to reduce this loss, adjusting the predicted probabilities to more closely match the distribution observed in the training data. As the training proceeds, a well trained model will assigned higher probability to more “likely” words (example - Rain, Candle, Forest etc) as shown in Figure 4b, than unlikely words (example Apple, Bella etc) as shown in Figure 4a.
We hence train GPT using the next token prediction over the internet. Let us called this pretrained model $π_{pretrained}$, with parameters $θ_{pretrained}$.
Level 2 - Supervised Fine-Tuning <Learn to Converse>

One-Glance Takeaway
Human conversations can be way more nuanced than, say, Wikipedia articles. Next, we go for supervised fine-tuning to make GPT more human-like. This is also a next token prediction task, expect now instead of predicting the next token of some generic text floating on the internet, we fine-tune GPT to predict the next tokens of real human conversations.

Supervised Finetuning Data, $D_{SFT}$
At this stage, human contractors are hired to generate answer prompts. One person mimics the user, while the other mimics an ideal chatbot. While we don’t have the details of the exact data used to fine-tune GPT, we can get some inspiration from one of its predecessor models, Instruct-GPT [2]. These prompts represent various tasks such as generation, Open QA, brainstorming etc (see Table 2a , 2b). These are then used to finetune GPT.
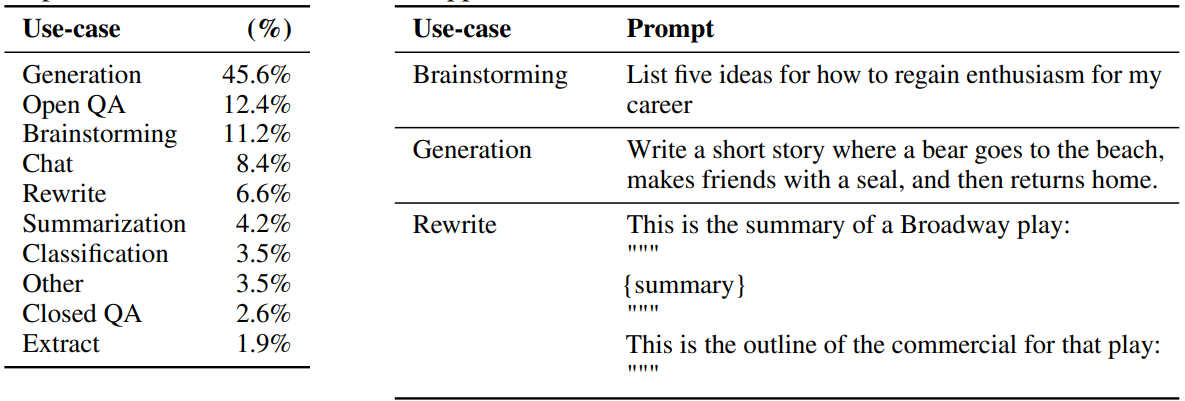
For each of these prompts, the human labelers are required to generate an ideal chatbot response (Table 2c).

Supervised Finetuning Objective
Given the input and an instruction, the concatenated input is fed into the model as a single string. Here is an example:
- User's Input: "Hello, how are you?"
- Task Instruction: "Translate the following sentence into French."
- Concatenated Input to Model: "Translate the following sentence into French: 'Hello, how are you?'"
Based on its training, the model understands that it needs to generate a translation of the sentence in French rather than, for example, summarizing the sentence or answering a question about it. Therefore, the model generates:
- Model's Output: "Bonjour, comment vas-tu?"
Let us called this fine-tuned model $π_{SFT}$, with parameters $θ_{SFT}$.
Level 3 - Training the Reward Model

One-Glance Takeaway
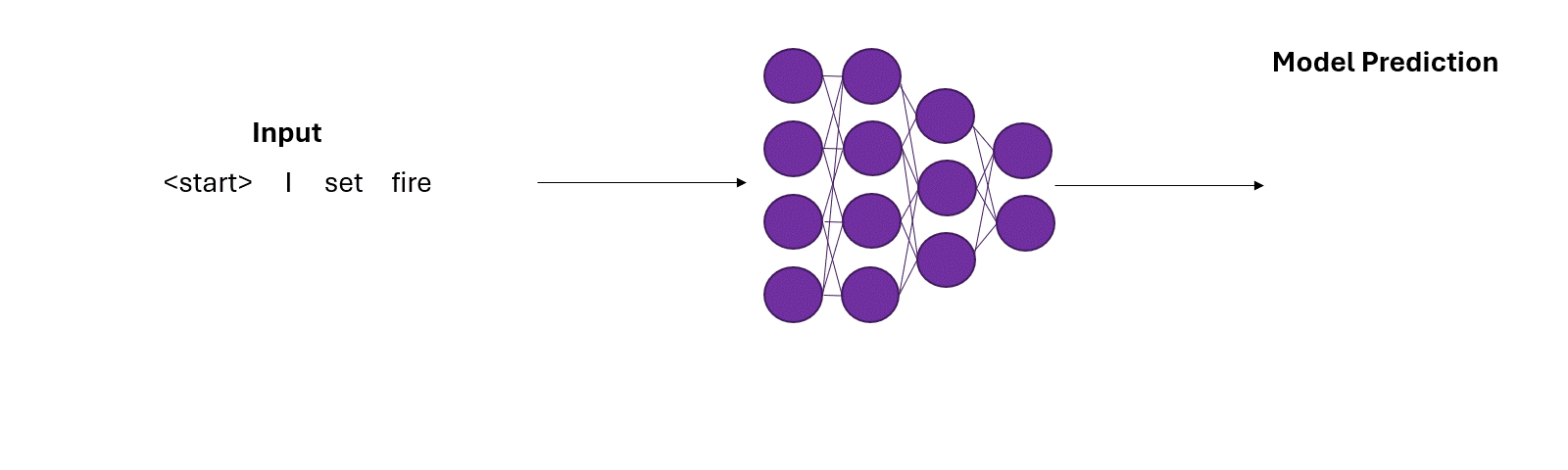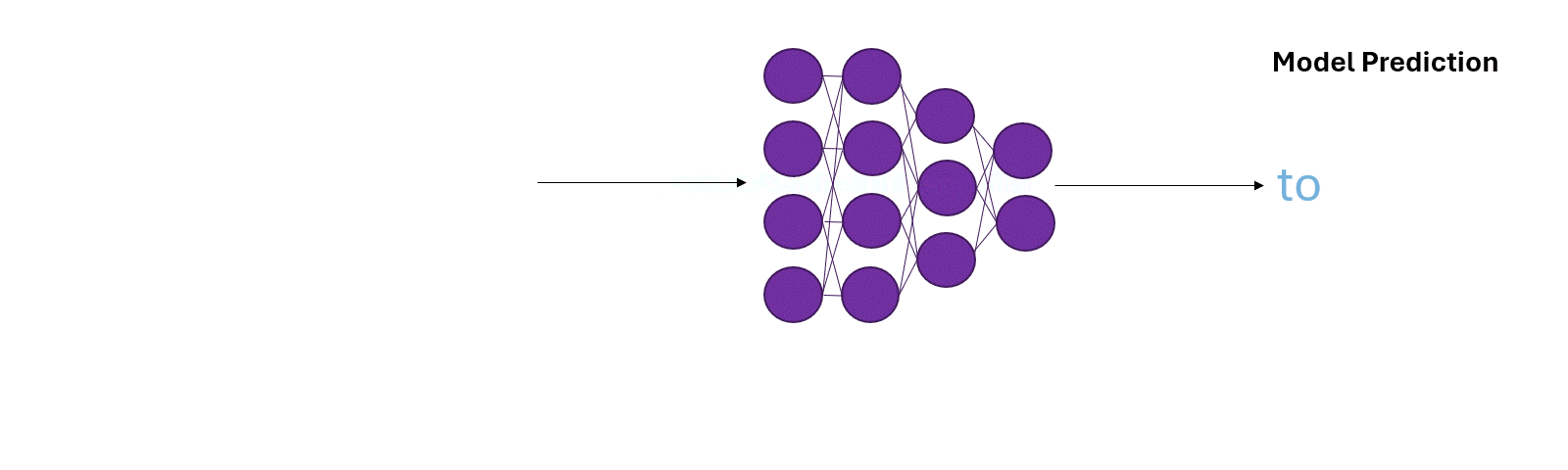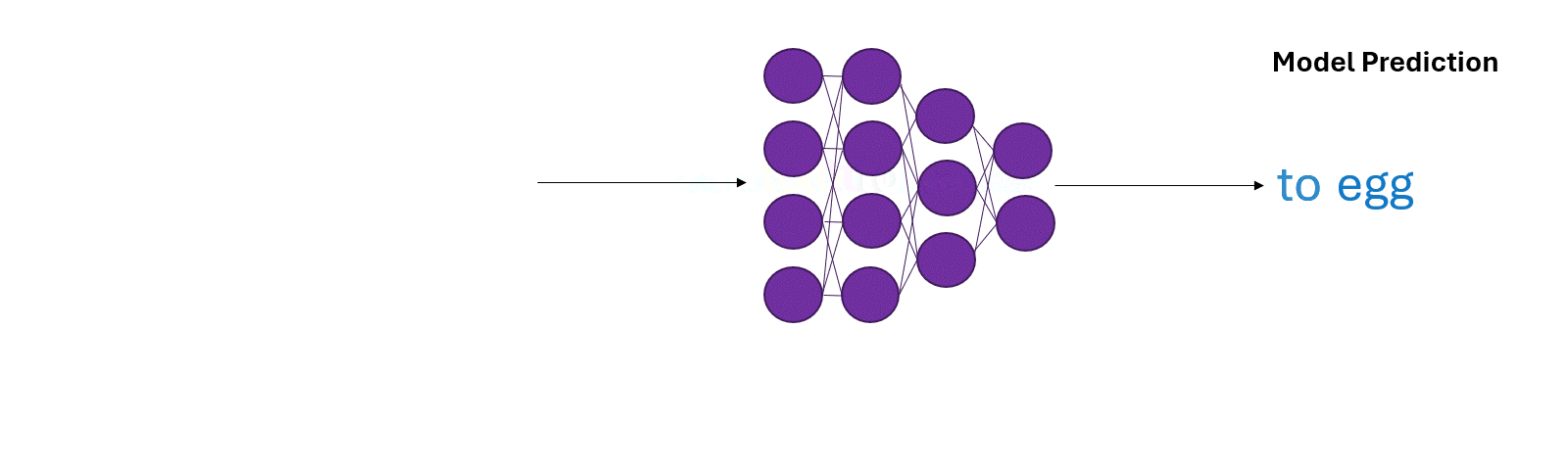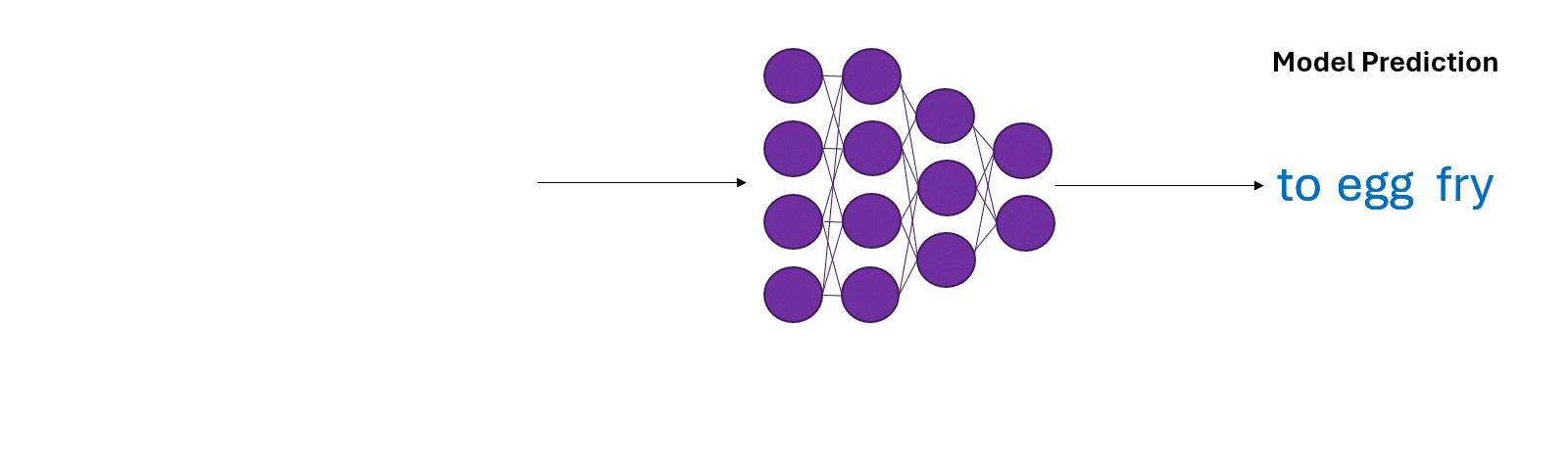
During the training phase, the model uses the training data to help fix its prediction mistakes as the training proceeds (Figure 6a).
During inference, however, the model has to rely on it’s own predictions. Mistakes during predictions can quickly compound over time steps (Figure 6b).
Before we let GPT ($π_{SFT}$) to independently serve you, we have a final step set in place to offer it feedback in real time as the GPT actively generates text. For this, we use reinforcement learning; more specifically the feedback of the reward model to update the parameters of GPT ($π_{SFT}$). And so it is not entirely inference and “kinda” another round of fine-tuning that makes GPT more attuned to human preferences as it generates responses.
Unlike supervised learning which optimizes for correct outputs at individual steps, reinforcement learning (RL) optimizes policies that consider the entire sequence of actions. This holistic approach enables the model to learn strategies that balance immediate rewards (e.g., a coherent response) with long-term goals (e.g., maintaining engagement over an entire conversation), accounting for the dependencies between successive actions).
Data to Train the Reward Model, $D_{RL}$
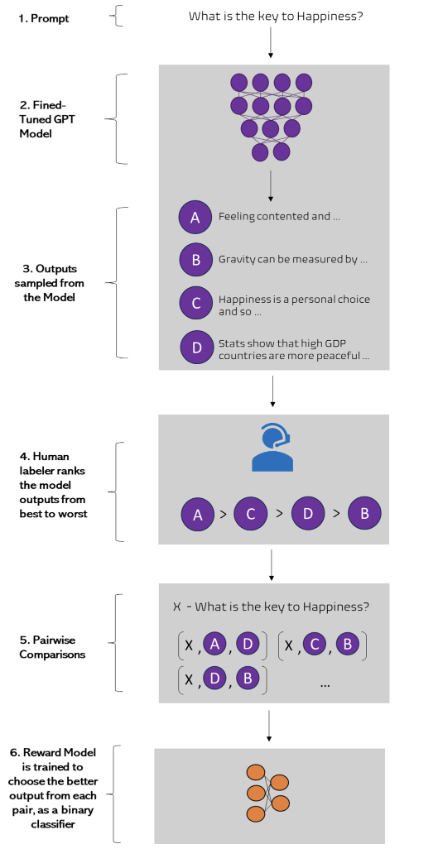
The complete procedure to obtain data for training the reward model is depicted in Figure 7.
1. Prompt - prompts are collected by human annotators.
2./3. Sampling Outputs - These prompts are fed into $π_{SFT}$ model and several responses by the model are collected.
4. Labeling Responses - Human evaluators are presented with these responses against a given prompt and asked to rank them from best to worst according to predefined scale based on various quality aspects (e.g., relevance, coherence, informativeness, creativity etc).
5. Pairwise Comparisons: Tuples of responses are generated against every prompt like so ($x$, $y_w$ , $y_l$), where $y_w$ is the preferred completion out of the pair.
6. Training the Reward Model: The reward model $π_{RL}$ is trained as a binary classifier to predict which of the $y$ responses is better.
Reward Model Training Objective
As discussed, we use the current version of the GPT model, $π_{SFT}$, to generate responses. Let's say it generates two candidate responses for the input:
- $y_1$ : "I don't read books."
- $y_2$ : "I love Dune for its deep exploration of politics and ecology in a sci-fi setting."
We then use the reward model, $π_{RL}$, to assign rewards to these responses:
- $r_θ(x,y_1)$ might be low, as it's not engaging.
- $r_θ(x,y_2)$ would be higher, reflecting a more engaging response
The loss function is defined as followed:
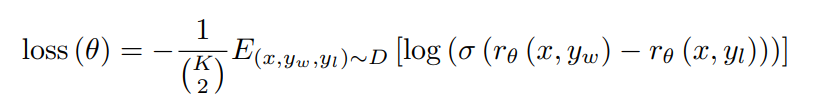
Where,
- x is the prompt,
- y is the fine-tuned model output pair, where $y_w$ is the preferred completion out of the pair of $y_w$ and $y_l$,
- θ are the reward model parameters,
- D is the dataset of human comparisons,
- $r_θ$ (x, y) is the scalar output of the reward model for prompt X and completion Y with parameters θ,
- σ is the sigmoid function transforming the logits to into a probability score, while the logarithm of this probability is taken to compute the log-likelihood, which is a common approach in binary classification problems to penalize incorrect predictions.
- The expectation E is computed by averaging the outcomes of the reward across all samples in D. Since we want the opposite of gradient descent algorithms (maximization of the objective function, instead of minimization), we take the negative of the log-likelihood,
- $(\frac {K} {2})$ represents the number of <$y_w$, $y_l$> pairs chosen per prompt x, per mini-batch*.* Dividing by it helps with normalization that brings some stability during training
Level 4 - Optimizing GPT using Reward Model <ChatGPT>

We use the reward score coming from the reward model $π_{RL}$ to update the GPT model $π_{SFT}$, aiming to increase the probability of generating responses like $y_2$ over $y_1$. We can conceptualize this step as adjusting the model's parameters so that engaging responses (as judged by the reward model) are more likely:
- If the model is more likely to produce $y_1$, we adjust its parameters to decrease its likelihood.
- Simultaneously, we adjust parameters to increase the likelihood of generating responses similar to $y_2$.
The environment is a bandit environment which presents a random customer prompt and expects a response to the prompt. Given the prompt and response, it produces a reward determined by the reward model and ends the episode. Additionally, per-token KL penalty is added from the GPT model $π_{SFT}$ at each token to mitigate overoptimization by the reward model.
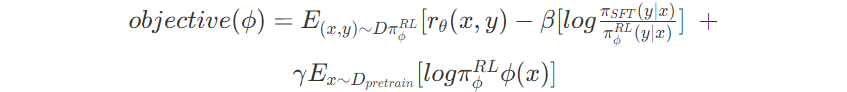
This equation encapsulates the RL objective of maximizing expected rewards while regularizing the policy to avoid straying too far from a supervised baseline and to maintain generalization to a pretraining distribution.
Here:
- $ϕ$ are the parameters of the RL policy.
- E denotes the expectation over the specified distribution.
- $Dπ_ϕ^{RL}$ represent the data samples under the RL policy
- $r_θ(x,y)$ is the reward for an input-output pair as predicted by the reward model with parameters θ.
- β is a coefficient weighting the regularization term that discourages large deviations from the supervised fine-tuning policy $π_{SFT}$
- $γ$ is a coefficient weighting the term that encourages the RL policy to give high likelihood to inputs similar to the pretraining data.
- $π_ϕ^{RL}(y∣x)$ is the probability of choosing output y given input x under the RL policy.
- $π_{SFT}(y∣x)$ is the probability of choosing output y given input x under the supervised fine-tuning policy
- $D_{pretrain}$ represents the inputs from the pre-training dataset.
Level 4 - Optimizing GPT using Reward Model <ChatGPT>

And lo and behold - we hence arrive at out final model, ChatGPT! Here is a quick final summary -
- Level 1 - Pre-train GPT using the internet ($D_{pretrain}$). The resultant model ($π_{pretrain}$) understands language in general.
- Level 2 - Supervised Finetuning of the pre-trained GPT using human conversations ($D_{SFT}$). The resultant model ($π_{SFT}$) becomes attuned to human conversations.
- Level 3 - Train a Reward Model ( $π_{RL}$) to rank the responses of the fine-tuned GPT ($π_{SFT}$) using rankings curated by humans ($D_{RL}$).
- Level 4 - Further optimize fine-tuned GPT using the Reward Model to favor human preferences. This gives as ChatGPT! 🙂
References

[1] Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A. and Agarwal, S., 2020. Language models are few-shot learners. Advances in neural information processing systems, 33, pp.1877-1901.
[2] Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A. and Schulman, J., 2022. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35, pp.27730-27744.
About Traversaal.ai
Search is evolving into complex search and Traversaal is the right tool to serve that evolving demand. Traversaal.ai is an innovative B2B platform startup specializing in Large Language Model (LLM) powered products.
Our primary offerings include a comprehensive conversational application with advanced features like authentication, session management, document retrieval, and web search.
Additionally, we provide versatile APIs that seamlessly integrate into organizational ecosystems, enabling the development of robust, domain-specific solutions.
Please email us at hello@traversaal.ai for any queries.